先来熟悉 Rust 中所有的标量类型(Scale Types):
Unsupported Notion block: table
标量类型也叫字面量类型,或者叫值类型,在寄存器中也叫立即数,特点是内存中保存的是值本身(&str 除外)。
fn main() {
let x = 2.0; // f64
let y: f32 = 3.0; // f32
let s: &str = "abc";
}x 变量会在main函数栈上占8字节的内存地址空间,其中保存的是 2.0 这个数值本身;y 类似。但是 s 不是这样的,虽然它也是标量类型。
Rust 中有两种字符串,&str 和 String ,&str 事实上是一个字符串切片(slice),是不可变类型(immutable)。String 是保存在堆上的可变字符串,底层是基于 Vec<T> 实现,这个后边讨论。
这里我们先讨论 &str ,这是 rust 中的字符串切片,先来看一段代码:
let s = String::from("hello world");
let hello = &s[0..5]; // &str 字符串切片
let world = &s[6..11]; // &str 字符串切片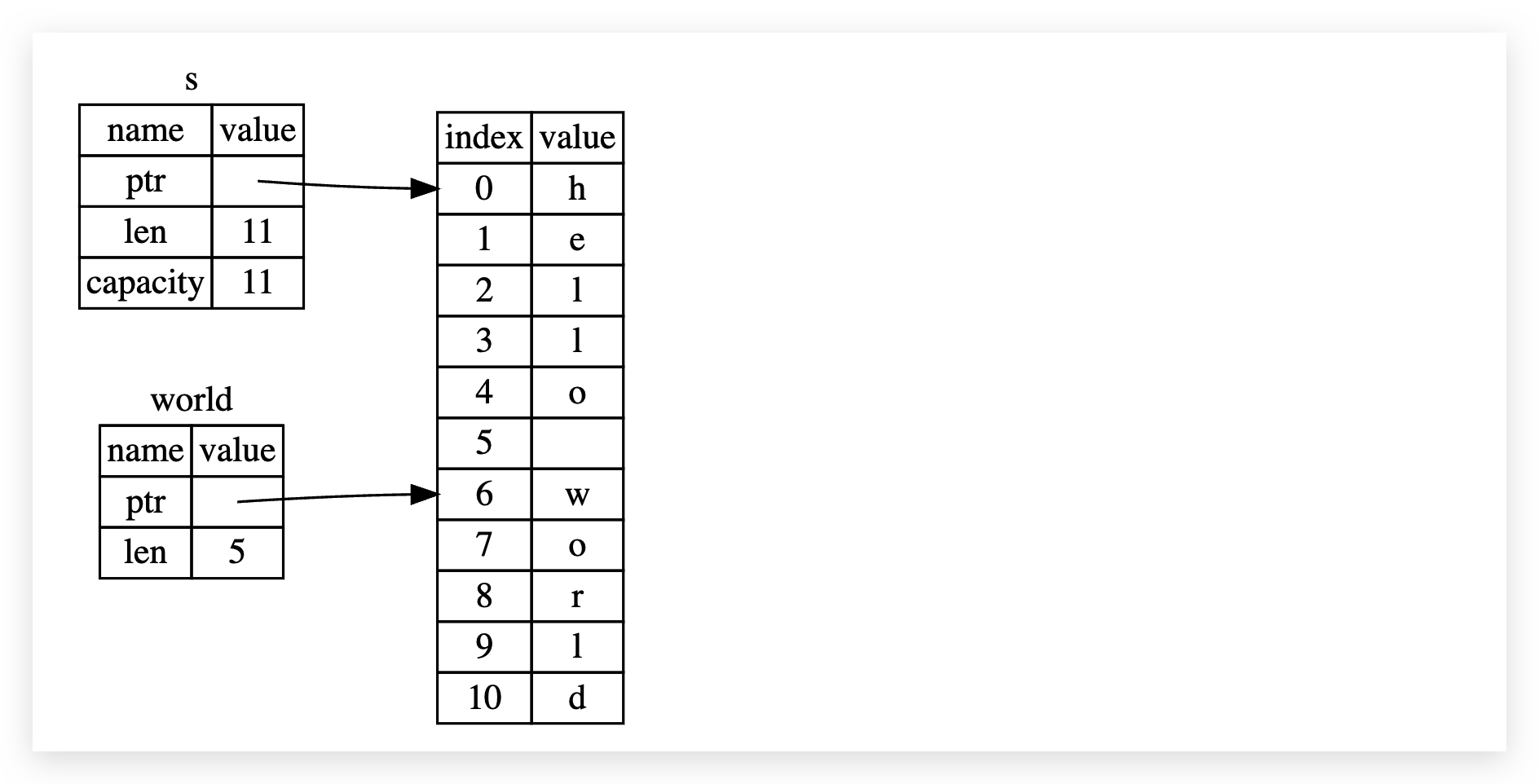
上边的 hello 和 world 都是切片(&str 类型);直观的看,字符串切片,就是一个指针,且包含了字节长度信息。上边的代码,&str 指向堆上的一部分字符串内存,所以叫做切片;因为有长度 len (字节为单位)限制,但没有容量,所以 &str 是一个不可变类型。
let sl: &str = "abc";
// sl.push("efg"); 错误操作,&str 是不可变的标量类型。我们也可以直接定义一个字符串切片,这次 “abc” 不是来自堆上的某块内存。而是直接找一段非栈上的空闲内存,存储 “abc”。sl 是不可变的,所以不可以增加,或者删除元素。
类型/行为
Rust 是一门类型安全的语言,为了保证这一点,Rust 使用两个概念,做更精致的设计:
- 类型
- 行为
Rust 中的类型非常精细,主要是为了编译期做更精准的安全检查。并给这些类型赋予特定的行为。
从抽象层面,Rust 的数据类型可以分为:
- 基本数据类型
- 自定义复合类型
- 容器类型
- 泛型
- 特定类型
前文提到的标量,都属于基本数据类型,有几点需要注意:
- usize 和 isize,分别表示无符号和有符合的指针类型,一般和计算机字长相等,32位字长,指针就是 4 字节;64位,指针为 8 字节。
- 元组的元素中只有一个值的时候,需要, 分割:(12,) ,这主要是为了和() 做区分
- Rust 中数组比较特殊,不同长度的数组是不同类型的数据。
引用
Rust 中也有类似 C 的原始指针(Raw Pointer),但是一般只能在 Unsafe Rust 中使用,Rust 推荐使用引用,这里总计一下,引用和原始指针的主要区别:
- 引用不可能为空
- 拥有生命周期
- 受借用检查器的保护,不会发生悬垂指针等问题。
Never 类型
代表不可能返回值的计算类型,在类型理论中,这个叫做底类型,底类型不包含任何值,但它可以合一到任何其他类型。合一的意思是,Never 类型好比数字 1 , 1 * x = x ,所以 Never 类型可以合一到任何其他类型。
Never 类型使用 ! 表示,在一些 Rust 内部系统中会经常使用 Never,例如:
let a = 12;
let b = if a % 2 == 0 {
true
} else {
panic!("不接受奇数");
};上边代码是可以正常编译的,原因是 panic 返回了 Never 类型,和 if 块要求的 bool 类型做了合一性,才能确保编译通过。
这里有个背景知识:由于 Rust 中 if…else 也是表达式,所以每个块表达式都必须返回相同的类型:
let b = if a % 2 == 0 {
true
} else {
1 // 编译报错
};这样的代码是无法编译的,因为 if 块返回的是 bool 值,表示整个 if…else 表达式的每个分支都需要返回 bool 类型的数据。这样才能确保 b 的类型是可确定的。但是前边的代码 panic! 却可以,原因就是 panic! 宏返回的是 Never 类型,Never 类型可以合一到任何其他类型。
由此也可以看出整个 Rust 代码就是表达式的集合,这点在后续的文章语法篇-面向表达式 会详细讨论。
结构体 & NewType
结构体一般分为:
- 具名结构体
- 元组结构体
- 单元结构体
// 具名结构体,即每个成员都会绑定一个名字:
struct Point {
x: i32,
y: i32,
}
// 元组结构体
struct Grade(i32)
// 单元结构体
struct Unit;元组结构体一般用来实现 NewType,例如上边的 Grade,用来和 i32 做区分。单元结构体一般用来做占位,特点是不管创建多少单元结构体,都是其自身。
结构体采用了内存对齐的布局方式,方便 CPU 寻址,对齐规则按照结构体中最大字节占用元素的字节倍数进行对齐。但是 Rust 一般都会做编译重排来实现内存优化:
struct A {
a: u8,
b: u32,
c: u16,
}
fn main() {
println!("{:?}", std::mem::size_of::<A>()); // 8
}理论上 b 占 4 字节,所以整个结构体 A 应该占 12(4 * 3)个字节,但实际打印确实 8 字节,原因是 Rust 做了编译重排:
struct A {
b: u32,
// a 和 c 合起来占 4 字节
a: u8,
c: u16,
// 再补齐一个字节
}如果不想让 Rust 做重排,可以通过内存布局属性#(repr(C))来指定:
#(repr(C))
struct A {
a: u8,
b: u32,
c: u16,
}
fn main() {
println!("{:?}", std::mem::size_of::<A>()); // 12
}此时,字节占用 12 个,这种方式也叫按 C 语言内存布局来指定。但现代编译期一般都会做结构体内存重排优化。
Copy
拷贝,是 Rust 中比较明确的概念,不像 C++ 或者其他语言,会存在深拷贝,浅拷贝,或者隐式拷贝等,Rust 中的拷贝就是简单的栈内容拷贝。
let x: i32 = 5;
let y = x; // 将 x 绑定的值 5,拷贝给 y; 现在 x 和 y 各有各的 5拷贝,就是内存层面的按位(bit) 拷贝,因为这些值都在栈上,所以拷贝开销非常小。所有的标量类型都实现 Copy Trait (Trait 是 Rust 中的特征,类似其他语言的接口)。
唯一需要注意的是 &str
let s1 = "abc";
let s2 = s1; // 将切片 s1 内存中的引用,按 bit 拷贝给 s2由于 &str 是切片,所以它的 Copy 实现略有不同
+-----+
s1 --> | ptr | --+-- "abc"
+-----+ |
| len | |
+-----+ |
|
|
+-----+ |
s2 --> | ptr | --
+-----+
| len |
+-----+其中 “abc” 存储在内存的 readonly 段。&str 实现的 copy,拷贝的是指针,s1 和 s2 保存了相同的指针,指向 “abc”。
对于引用类型的数据,需要管理内存,简单说,就是在作用域结束需要释放引用,所以不能 rust 基本不能对引用类型实现 copy。因为引用类型实现了 Drop trait。
可变和不可变
默认情况,rust 创建的都是不可变类型,意味着一旦给某个变量一个初始值,后续就不能再更改。
let x = 10;
x = 20; // 编译报错: cannot assign twice to immutable variable如果需要再后续的代码中修改,还需要使用mut 关键字:
let mut x = 10;
x = 20;Shadowing
Rust 支持变量覆盖定义(这是我的翻译):
fn main() {
let a = 4;
println!("(1) a is: {a}");
let a = a * 2;
println!("(2) a is: {a}");
{
let a = a + 6;
println!("(3) a is: {a}");
}
println!("(4) a is: {a}");
}
//result
Compiling playground v0.0.1 (/playground)
Finished dev [unoptimized + debuginfo] target(s) in 0.57s
Running `target/debug/playground`
Standard Output
(1) a is: 4
(2) a is: 8
(3) a is: 14
(4) a is: 8简单的说,就是运行在同一个作用域内,再次申明同名、同类型的变量:
let a = 4;
println!("(1) a is: {a}");
let a = a * 2; // shadowing,之后访问的 a 都是这个 a;
println!("(2) a is: {a}");组合类型
Array: Rust 中的数组是一组具有相同类型的数据,并且长度固定。
fn main() {
let arr: [i32; 5] = [34, 51, 11, 42, 87];
let result = arr[2]; // result = 11
}
// i32 is the type of the values
// 5 is the size of the array因为数组的长度必须是固定的,所以数组也是存储在栈上的。
Tuple: Rust 中,元组可以像数组一样,但是可以拥有不同的数据类型;但整体的数据大小是固定的。
fn main() {
let tup: (u64, f32, i8) = (902, 2.2, -1);
let result = tup.1; //result = 2.2
}泛型 Trait 行为
泛型,即参数化类型,也就是把具体类型参数化;但最终代码执行都需要再把类型单态化,也就是转换为具体类型。Rust 由于有类型推断,所以是在编译期完成的类型单态化的。
很多语言都有这种设定,只不过叫法不一样。Rust 把它称为 Trait,是一种宏观抽象,即行为。每种类型都有各自特定的行为,我们也可以自己抽象一些行为,但是要注意一些规则:
struct Point {
x: i32,
y: i32,
}
impl Point {
fn hello(&self) {
println!("x is: {}, y is: {}", self.x, self.y);
}
}
trait Hello {
fn hello(&self);
}
impl Hello for Point {
fn hello(&self) {
println!("hello in Trait");
}
}
fn main() {
let p = Point{x: 12, y: 13};
// 默认调用自己实现的 hello,输出 x is: 12, y is: 13
p.hello();
// 无歧义调用 Hello Trait 的 hello,输出 hello in Trait
<Point as Hello>::hello(&p);
}这事实上也是一种函数重载,只不过 Rust 对使用规则更加明确。
(本节完)